Status: Article in progress
Prehistory
What is your batch size? When I did tests for parsing csv and write to CH (now on Github), I saw that I have some variables: ring buffer size and batch size of Clickhouse driver, which I don’t know apriory, because ring buffer size is a CPU L3 cache size and batch size depends on many factors, even on my laptop it could be changed depends on logging settings. And I realized that we could have another familly of applications, which should define their parameters dynamically at runtime.
Think about it
Let’s imagine what does influence on batch size of application? If your database is remote, then it is at least network connection. If your database is local, then it is disk speed. What else? You also could mention branch predictions, cache coherence, false sharing and other effects reffered to multithreading processing, where batches decrease thread switches. What else? If you use compressing to reduce IO you should find batch size as a golden middle between CPU load and compressing. Or just row size. Really, when we set batch size we don’t think about that, generally. There are many effects and reasons. And all of them could be changed from x86 to x64 or PowerPC, or from node to node, or even on one node by different performance profile and load.
Batch size is only one variable. For instance, if we create parsing application, which read file → parse → write to database in multiple threads (typically two threads with pipe streams), there will new parameters – queue sizes for threads. So we could have a set of parameters, which influence on one big task.
So who know what should batch size equal? The only answer is runtime. Moreover, theoretically runtime could determine what batch size is best in particular scenarious (when we have different load on server, for instnace).
What we have?
In modern live it makes sense to suppose that someone already did it for us. I found this articles:
They talk about IoT and something close, but not the same. The difference is above articles are about collecting data from devices, and I’m talking about application. Maybe from some point of view is the same, because I also mean that we have some device (computer), where we run application and collect feedbacks. But the main difference is it’s not about machines only. People also could participate in this process. Also in practice it could be not about “big data”. For big data we need a lot of experiments, and our dynamic algorithms should be responsive enough and appropriate even we don’t have too much collected data. From the other side there are many runtime optimizations in JIT and HotSpot too, but this article about higher layer.
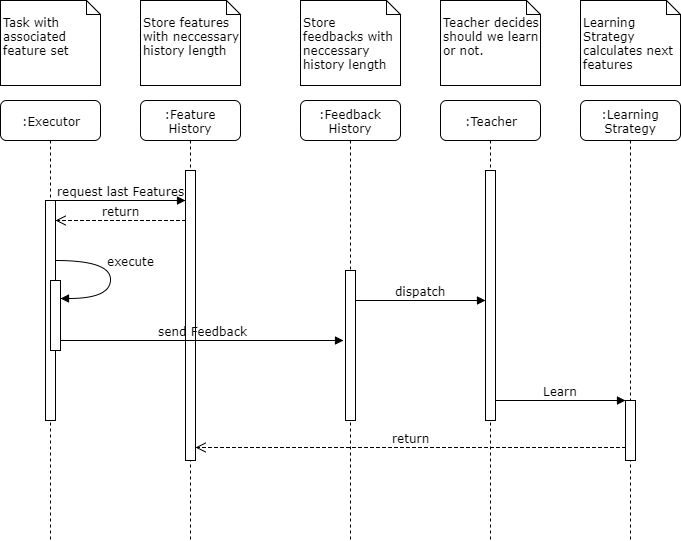
Algorithm
Let’s describe simple model, which will represent and solve the task of batch size (from the start).